Jobflow engine
The Jobflow adaptor maps tasks to Jobflow jobs, letting you integrate with materials-science pipelines and store rich provenance alongside Jobflow execution metadata.
Installation
Install the Jobflow extra:
pip install node_graph_engine[jobflow](Optional) Configure a Jobflow
JobStore(for example aMongoStore) if you want persistent storage beyond the default in-memory execution used byjobflow.run_locally().Load an AiiDA profile prior to launching the engine.
Example
from aiida import load_profile
from node_graph import task
from node_graph_engine.engines.jobflow import JobflowEngine
load_profile()
@task()
def add(x, y):
return x + y
@task()
def multiply(x, y):
return x * y
@task.graph()
def add_then_multiply(x, y, z):
the_sum = add(x=x, y=y).result
return multiply(x=the_sum, y=z).result
graph = add_then_multiply.build(x=1, y=2, z=3)
engine = JobflowEngine(name="jobflow-quick-start")
outputs = engine.run(graph)
print(outputs)
Jobflow executes the jobs locally by default.
Use AiiDA commands to inspect the processes and their provenance:
verdi process list -a
Which will show something like:
2222 4s ago NodeGraph<add_then_multiply> ⏹ Finished [0]
2223 4s ago add ⏹ Finished [0]
2225 4s ago multiply ⏹ Finished [0]
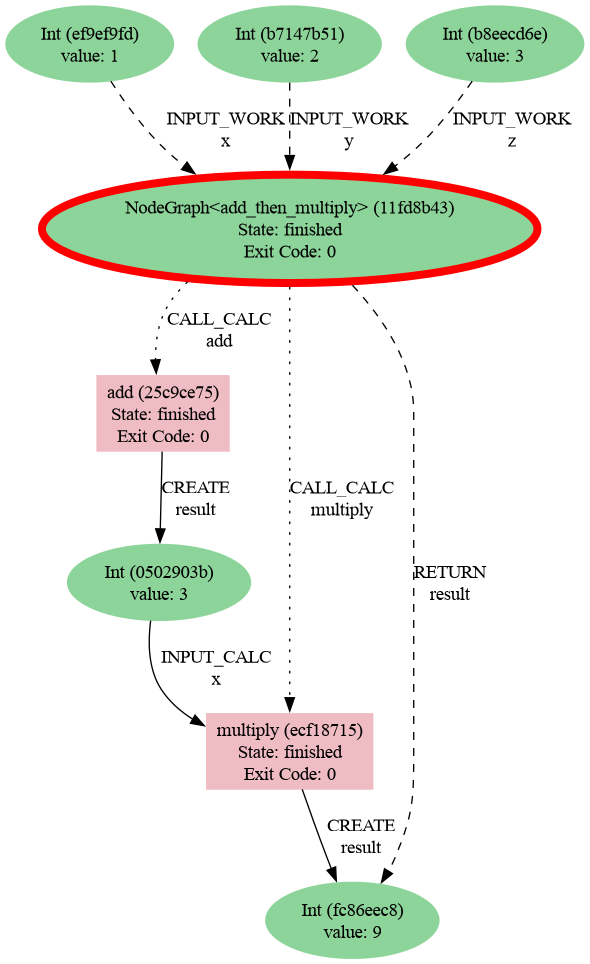
Then generate a provenance graph for a workflow:
verdi node graph generate 2222 -f png
Here is the resulting graph: